Há algum tempo, escrevi aqui um post sobre um mini projeto que desenvolvi com o intuito de capturar da página do Itamaraty os discursos dos três últimos presidentes brasileiros. Neste novo post descrevo alguns resultados dessa pequena análise, onde foi preciso empregar técnicas de data cleaning, processamento de linguagem natural, algoritmos de classificação e de regressão linear.
Para ter uma primeira visão do conteúdo dos discursos, é interessante olhar para as palavras que mais de repetem. Podemos fazer isso de diversas maneiras, dentre elas por meio de uma nuvem de palavras. Considerando o conjunto de discursos de cada presidente (Temer, Dilma e Lula) como uma bag of words e após proceder com uma filtragem de stopwords (palavras sem significância, numa primeira aproximação) temos:


Uma maneira alternativa, é recorrer ao chamado gráfico de frequências. Assim tomando as 20 palavras mais frequêntes, temos para os três presidentes:
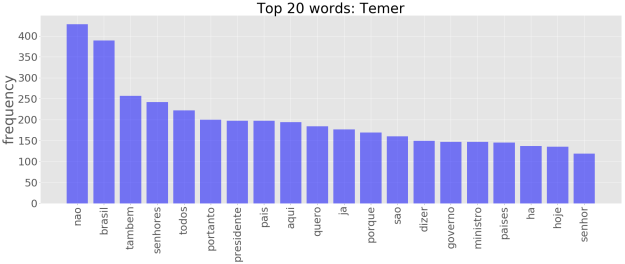
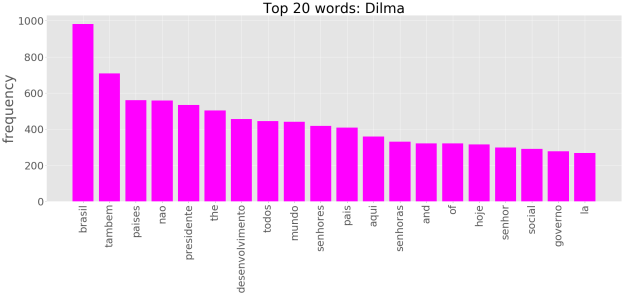
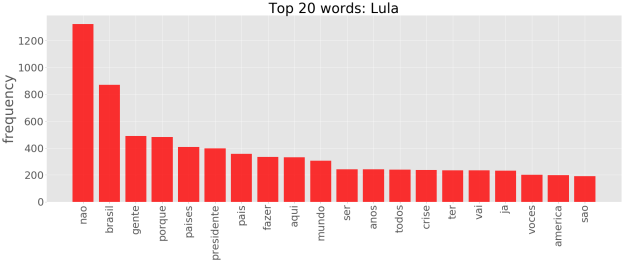
No entanto, olhar apenas para palavras individuais pode passar uma idéia bastante limitada da significação contextual de um dado texto. Um passo além é olhar para os n-gramas. Um n-grama pode ser definido como um conjunto de n palavras adjacentes dentro de um texto. Considerando bigramas, temos:
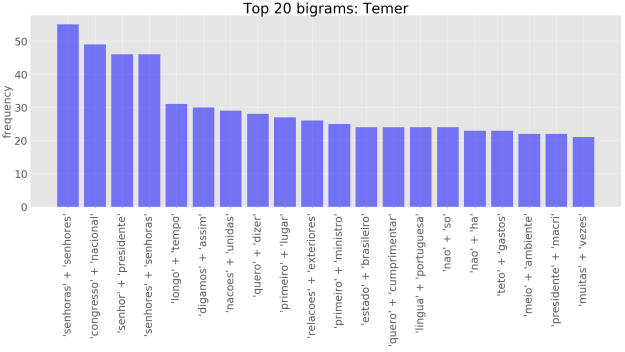
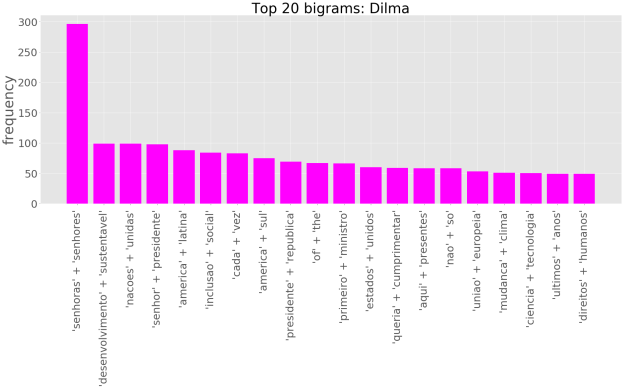
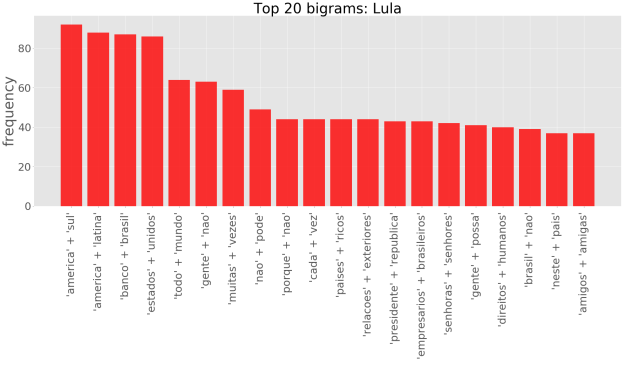
Podemos, por exemplo, perceber que o Temer e a Dilma costumam usar a mesma saudação, “senhoras e senhores”. Além disso, Temer, “digamos assim”, parece estar bastante preocupado com “Congresso Nacional”, enquanto que a Dilma com o “desenvolvimento sustentável”, e Lula com a “américa do sul” e a “américa latina”.
Outra quantidade interessante a ser medida é a chamada diversidade lexical (DL). A DL pode ser definida como a razão entre o número de palavras únicas e o número total de palavras utilizadas num dado texto. Essa métrica pode ser interpretada como um indicativo da extensão do vacubulário de uma pessoa, num dado pronunciamento. Quanto maior o valor da DL, maior tende a ser o emprego de palavras únicas. Considerando ainda os discursos de cada preseidente como um todo, temos:
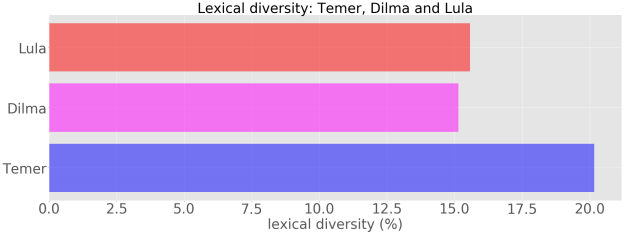
Podemos notar que a DL dos discursos do Temer é de cerca de aproximadamente 20%, enquanto que nos discursos da Dilma e do Lula, temos uma DL de cerca de 15%, com uma leve vantagem para o Lula. Cabe ressaltar que não necessariamente é o próprio presidente quem escreve seus discursos. Muitas vezes existe um profissional destinado a esta função, chamado de speechwriter. Por exemplo, Jon Favreau foi o coordenador da equipe de speechwriters de Barack Obama: https://en.wikipedia.org/wiki/Jon_Favreau_(speechwriter).
É interessante olharmos também para as características de cada discurso de forma individual, ao invés de considerarmos apenas o todo. Considerando então cada discurso como uma entrada, temos as seguintes distribuições de probabilidade para a DL:
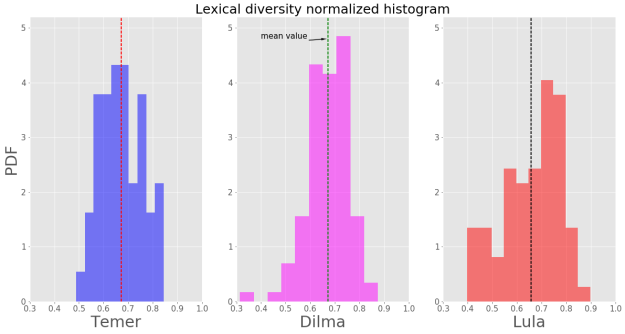
Podemos notar na figura acima que os discursos de Temer possuem menor dispersão ao redor da média (linha vetical tracejada), se comparados aos discursos de Dilma e Lula.
Se tomarmos como variáveis aleatórias a DL e a contagem do número de palavras numa dada entrada (discurso), nossa intuição diz que, quanto maior o número de palavras num texto, menor tende a ser a DL do mesmo. Ou seja, essas duas variáveis parecem ser correlacionadas de forma significativa. Será que isso também ocorre nos discursos presidenciais? A resposta é sim:
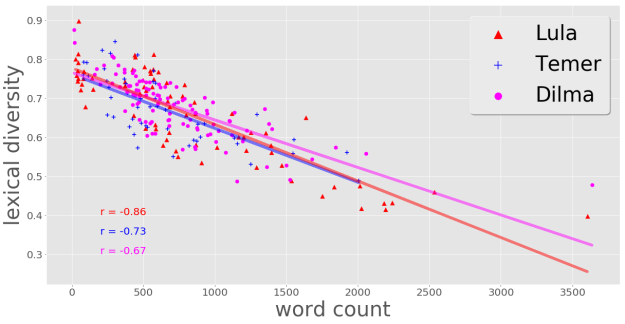
No gráfico de dispersão acima temos que a relação estatística entre as duas variáveis mencionadas parece ser linear, conforme as linhas de tendência ajustadas aos dados de cada presidente ajudam a enxergar. No canto inferior esquerdo temos os respectivos coeficientes de correlação linear, indicando que os dados do Lula são os mais fortemente correlacionados de forma linear.
Por fim, imagine que não sabemos de quem são os discursos proferidos pelo Temer, e queremos que um robô ou uma inteligência artificial os classifique como sendo da Dilma ou do Lula. O gráfico abaixo mostra o resultado desse procedimento de análise preditiva supervisionada obtido usando o algoritmo de regresão logística como modelo de classificação:
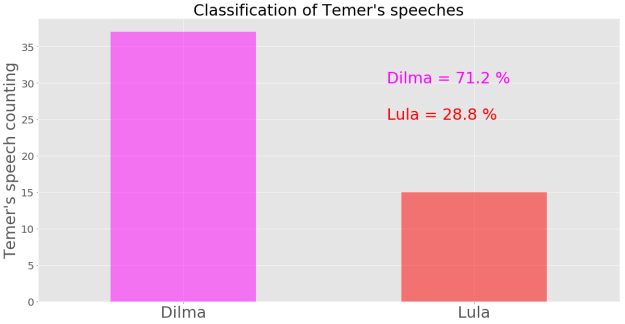
Ou seja, o modelo utilizado classificou 71.2% dos discursos do Temer como sendo da Dilma, e os 28,8% restante, como sendo do Lula. Para ter uma idéia do quanto “em cima do muro” o modelo ficou, podemos olhar para as probabilidades inferidas pelo modelo preditivo. Levanto em conta que probabilidade igual a 0 foi definida como certeza que o discurso não é da Dilma (e, portanto é do Lula) e que probabiliade igual a 1 significa certeza de que o discurso é da Dilma (e, portanto, não é do Lula) , temos:
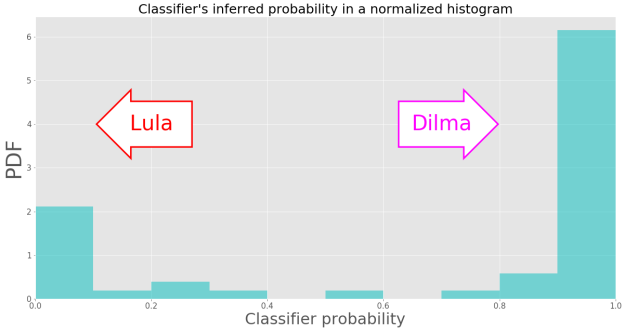
Portanto, como os resultados estão bastante dispersos ao redor do valor central possível (0,5), podemos dizer que o modelo até que foi bem convicto, não tendo ficado muito em cima do muro 🙂
O código fonte utilizado nesta análise encontra-se publicado no repositório https://github.com/lasleandro/presidential-speeches_classifier.
Quaisquer dúvidas e sugestões, fique livre para escrever!
